struct _IO_FILE { int _flags; /* High-order word is _IO_MAGIC; rest is flags. */ #define _IO_file_flags _flags
/* The following pointers correspond to the C++ streambuf protocol. */ /* Note: Tk uses the _IO_read_ptr and _IO_read_end fields directly. */ char* _IO_read_ptr; /* Current read pointer */ char* _IO_read_end; /* End of get area. */ char* _IO_read_base; /* Start of putback+get area. */ char* _IO_write_base; /* Start of put area. */ char* _IO_write_ptr; /* Current put pointer. */ char* _IO_write_end; /* End of put area. */ char* _IO_buf_base; /* Start of reserve area. */ char* _IO_buf_end; /* End of reserve area. */ /* The following fields are used to support backing up and undo. */ char *_IO_save_base; /* Pointer to start of non-current get area. */ char *_IO_backup_base; /* Pointer to first valid character of backup area */ char *_IO_save_end; /* Pointer to end of non-current get area. */
struct _IO_marker *_markers;
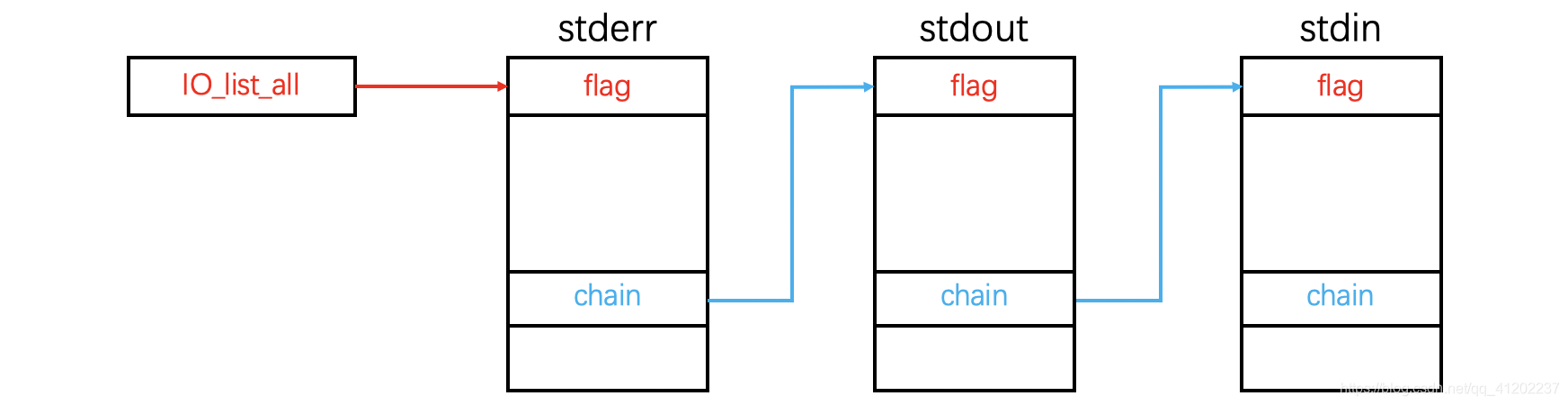
struct _IO_FILE *_chain;
int _fileno; #if 0 int _blksize; #else int _flags2; #endif _IO_off_t _old_offset; /* This used to be _offset but it's too small. */
#define __HAVE_COLUMN /* temporary */ /* 1+column number of pbase(); 0 is unknown. */ unsignedshort _cur_column; signedchar _vtable_offset; char _shortbuf[1];
if (n <= 0) return0; /* This is an optimized implementation. If the amount to be written straddles a block boundary (or the filebuf is unbuffered), use sys_write directly. */
/* First figure out how much space is available in the buffer. */ if ((f->_flags & _IO_LINE_BUF) && (f->_flags & _IO_CURRENTLY_PUTTING)) { count = f->_IO_buf_end - f->_IO_write_ptr; if (count >= n)//缓冲区长度大于数据长度 { constchar *p; for (p = s + n; p > s; ) { if (*--p == '\n')//寻找数据的结尾,并更新为count { count = p - s + 1; must_flush = 1; break; } } } } elseif (f->_IO_write_end > f->_IO_write_ptr) count = f->_IO_write_end - f->_IO_write_ptr; /* Space available. */
/* Then fill the buffer. */ if (count > 0) { if (count > to_do) count = to_do; f->_IO_write_ptr = __mempcpy (f->_IO_write_ptr, s, count); s += count; to_do -= count;//to_do = 0 } if (to_do + must_flush > 0)//刷新缓冲区 { size_t block_size, do_write; /* Next flush the (full) buffer. */ if (_IO_OVERFLOW (f, EOF) == EOF) /* If nothing else has to be written we must not signal the caller that everything has been written. */ return to_do == 0 ? EOF : n - to_do;
/* Try to maintain alignment: write a whole number of blocks. */ block_size = f->_IO_buf_end - f->_IO_buf_base; do_write = to_do - (block_size >= 128 ? to_do % block_size : 0);
if (do_write) { count = new_do_write (f, s, do_write); to_do -= count; if (count < do_write) return n - to_do; }
/* Now write out the remainder. Normally, this will fit in the buffer, but it's somewhat messier for line-buffered files, so we let _IO_default_xsputn handle the general case. */ if (to_do) to_do -= _IO_default_xsputn (f, s+do_write, to_do); } return n - to_do; } libc_hidden_ver (_IO_new_file_xsputn, _IO_file_xsputn)
int _IO_new_file_overflow (FILE *f, int ch) { if (f->_flags & _IO_NO_WRITES) /* SET ERROR */ { f->_flags |= _IO_ERR_SEEN; __set_errno (EBADF); return EOF; } /* If currently reading or no buffer allocated. */ if ((f->_flags & _IO_CURRENTLY_PUTTING) == 0 || f->_IO_write_base == NULL) { /* Allocate a buffer if needed. */ if (f->_IO_write_base == NULL) { _IO_doallocbuf (f); _IO_setg (f, f->_IO_buf_base, f->_IO_buf_base, f->_IO_buf_base); } /* Otherwise must be currently reading. If _IO_read_ptr (and hence also _IO_read_end) is at the buffer end, logically slide the buffer forwards one block (by setting the read pointers to all point at the beginning of the block). This makes room for subsequent output. Otherwise, set the read pointers to _IO_read_end (leaving that alone, so it can continue to correspond to the external position). */ if (__glibc_unlikely (_IO_in_backup (f))) { size_t nbackup = f->_IO_read_end - f->_IO_read_ptr; _IO_free_backup_area (f); f->_IO_read_base -= MIN (nbackup, f->_IO_read_base - f->_IO_buf_base); f->_IO_read_ptr = f->_IO_read_base; }
if (fp->_IO_buf_base == NULL) { /* Maybe we already have a push back pointer. */ if (fp->_IO_save_base != NULL) { free (fp->_IO_save_base); fp->_flags &= ~_IO_IN_BACKUP; } _IO_doallocbuf (fp); }
while (want > 0) { have = fp->_IO_read_end - fp->_IO_read_ptr; if (want <= have) { memcpy (s, fp->_IO_read_ptr, want); fp->_IO_read_ptr += want; want = 0; } else { if (have > 0) { s = __mempcpy (s, fp->_IO_read_ptr, have); want -= have; fp->_IO_read_ptr += have; }
/* Check for backup and repeat */ if (_IO_in_backup (fp)) { _IO_switch_to_main_get_area (fp); continue; }
/* If we now want less than a buffer, underflow and repeat the copy. Otherwise, _IO_SYSREAD directly to the user buffer. */ if (fp->_IO_buf_base && want < (size_t) (fp->_IO_buf_end - fp->_IO_buf_base)) { if (__underflow (fp) == EOF) break;
continue; }
/* These must be set before the sysread as we might longjmp out waiting for input. */ _IO_setg (fp, fp->_IO_buf_base, fp->_IO_buf_base, fp->_IO_buf_base); _IO_setp (fp, fp->_IO_buf_base, fp->_IO_buf_base);
/* Try to maintain alignment: read a whole number of blocks. */ count = want; if (fp->_IO_buf_base) { size_t block_size = fp->_IO_buf_end - fp->_IO_buf_base; if (block_size >= 128) count -= want % block_size; }
if (fp->_IO_buf_base == NULL) { /* Maybe we already have a push back pointer. */ if (fp->_IO_save_base != NULL) { free (fp->_IO_save_base); fp->_flags &= ~_IO_IN_BACKUP; } _IO_doallocbuf (fp); }
/* FIXME This can/should be moved to genops ?? */ if (fp->_flags & (_IO_LINE_BUF|_IO_UNBUFFERED)) { /* We used to flush all line-buffered stream. This really isn't required by any standard. My recollection is that traditional Unix systems did this for stdout. stderr better not be line buffered. So we do just that here explicitly. --drepper */ _IO_acquire_lock (stdout);
/* This is very tricky. We have to adjust those pointers before we call _IO_SYSREAD () since we may longjump () out while waiting for input. Those pointers may be screwed up. H.J. */ fp->_IO_read_base = fp->_IO_read_ptr = fp->_IO_buf_base; fp->_IO_read_end = fp->_IO_buf_base; fp->_IO_write_base = fp->_IO_write_ptr = fp->_IO_write_end = fp->_IO_buf_base;
count = _IO_SYSREAD (fp, fp->_IO_buf_base, fp->_IO_buf_end - fp->_IO_buf_base); if (count <= 0) { if (count == 0) fp->_flags |= _IO_EOF_SEEN; else fp->_flags |= _IO_ERR_SEEN, count = 0; } fp->_IO_read_end += count; if (count == 0) { /* If a stream is read to EOF, the calling application may switch active handles. As a result, our offset cache would no longer be valid, so unset it. */ fp->_offset = _IO_pos_BAD; return EOF; } if (fp->_offset != _IO_pos_BAD) _IO_pos_adjust (fp->_offset, count); return *(unsignedchar *) fp->_IO_read_ptr; }
/* We do it this way to handle recursive calls to exit () made by the functions registered with `atexit' and `on_exit'. We call everyone on the list and use the status value in the last exit (). */ while (true) { structexit_function_list *cur = *listp;
if (cur == NULL) { /* Exit processing complete. We will not allow any more atexit/on_exit registrations. */ __exit_funcs_done = true; break; }
case ef_free: case ef_us: break; case ef_on: onfct = f->func.on.fn; arg = f->func.on.arg; #ifdef PTR_DEMANGLE PTR_DEMANGLE (onfct); #endif /* Unlock the list while we call a foreign function. */ __libc_lock_unlock (__exit_funcs_lock); onfct (status, arg); __libc_lock_lock (__exit_funcs_lock); break; case ef_at: atfct = f->func.at; #ifdef PTR_DEMANGLE PTR_DEMANGLE (atfct); #endif /* Unlock the list while we call a foreign function. */ __libc_lock_unlock (__exit_funcs_lock); atfct (); __libc_lock_lock (__exit_funcs_lock); break; case ef_cxa: /* To avoid dlclose/exit race calling cxafct twice (BZ 22180), we must mark this function as ef_free. */ f->flavor = ef_free; cxafct = f->func.cxa.fn; arg = f->func.cxa.arg; #ifdef PTR_DEMANGLE PTR_DEMANGLE (cxafct); #endif /* Unlock the list while we call a foreign function. */ __libc_lock_unlock (__exit_funcs_lock); cxafct (arg, status); __libc_lock_lock (__exit_funcs_lock); break; }
if (__glibc_unlikely (new_exitfn_called != __new_exitfn_called)) /* The last exit function, or another thread, has registered more exit functions. Start the loop over. */ continue; }
*listp = cur->next; if (*listp != NULL) /* Don't free the last element in the chain, this is the statically allocate element. */ free (cur); }
__libc_lock_unlock (__exit_funcs_lock);
if (run_list_atexit) RUN_HOOK (__libc_atexit, ());
#ifdef SHARED int do_audit = 0; again: #endif for (Lmid_t ns = GL(dl_nns) - 1; ns >= 0; --ns) { /* Protect against concurrent loads and unloads. */ __rtld_lock_lock_recursive (GL(dl_load_lock));
unsignedint nloaded = GL(dl_ns)[ns]._ns_nloaded; /* No need to do anything for empty namespaces or those used for auditing DSOs. */ if (nloaded == 0 #ifdef SHARED || GL(dl_ns)[ns]._ns_loaded->l_auditing != do_audit #endif ) __rtld_lock_unlock_recursive (GL(dl_load_lock));